Leveraging Insurance Data, Part 2: A Single Source of the Truth
In the first article of this series, we described the importance of understanding data. We looked at an example of an insurance company that was preparing to implement a document generation system. By doing so it discovered an indexing data structure that would satisfy the immediate goal of indexing document images and that could also be leveraged to index any list of items for the enterprise. With this future-state indexing data structure in hand, the team then determined how to align the current systems with this new structure.
We looked at the existing application integrations with the imaging system. But when there are multiple versions of this indexing data, a number of challenges are present. From the business user perspective, it becomes confusing to understand what system to use to gather the information needed. In all likelihood there are variations of the data in each system, and now the business users must learn where to go for the information they need. This corporate knowledge of where to go for the data needed vanishes when the knowledgeable employee leaves.
From the technical perspective there are many challenges as well. Where should an application go to get the data needed? If there is a discrepancy between two data sources, what rules are needed to resolve the discrepancy? Of course, the systems can be made to work. However, the cost and resources to maintain the systems increase in proportion to the complexity of the integrations. This is the importance behind the architectural principle of establishing a "Single Source of Truth": The IT architecture will enable solutions that provide a consistent, integrated view of the business, regardless of access point.
When no authoritative set of data governs a certain area of the business, there is a tendency toward data sprawl, and many different versions of the truth can arise. In the indexing example, there was index data in the claim system, the policy system, and the archive system prior to the change.
The indexing data was viewed as a well defined set of company-specific data that could be used to integrate front-end and back-end components. The decision was made to manage this data in its own schema. By segregating this data there would be an increase in flexibility to respond to business needs because it would no longer be subject to the upgrade path or data structures that are present when the data is maintained within a commercial product. Because this data truly was specific to the company, it made sense for the company to control the structure and how it was populated.
The next step was to migrate the existing data into the new data structure. This can be a time-intensive process, because it is in this step that all the shortcomings from previous integrations become obvious. Missing data must be created; conflicting data must be resolved; incorrect data must be researched and corrected. It's like building a house: Lots of time and effort go into building the foundation, yet all this work is covered up and seldom seen. The same can be said for the work to conform the data to the desired structure. Few people will ever point to the structure and say, “Wow, what a nice data structure!” Yet this is exactly the work that will provide the foundation for many business advantages.
Once all the existing data had been migrated, the indexing system became the single source of truth for the company’s indexing data. Some of the other applications required a subset of this data to work properly. Jobs were created to populate these applications from the indexing data so the application data would always be consistent with the single source of truth.
The end result is shown below. Notice there is one location for the image metadata. There is no longer a need to search multiple systems to generate a list of document images, or conflicting data about the indexing information, so no time is spent figuring out what data is correct between two different sources. No corporate knowledge is necessary to determine where to look for the data and what data to use. Because the indexing data structure is well defined, we can be assured the data is consistent and accurate across all document images. Also notice that there is only one integration point with the imaging system, significantly reducing the number of integration licenses required.
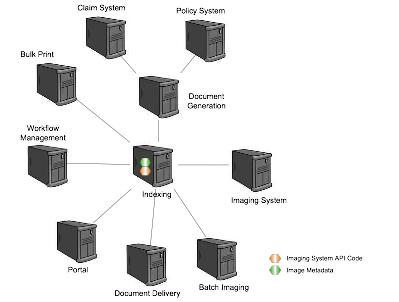
You may have noticed that it takes a little more than the principle of having a Single Source of Truth to get from the image in the first article to the one here, and you would be correct. We'll cover that in the next article.
Andy Metroka is the Director of IT Architecture responsible for systems, application, and database architecture at Montana State Fund, which provides workers compensation insurance for Montana businesses. Prior to that Andy was a software consultant where he designed and ... View Full Bio